Publication
2026
- UrbanVerse: Scaling Urban Simulation by Watching City-Tour VideosInternational Conference on Learning Representations (ICLR), 2026
- From Seeing to Experiencing: Scaling Navigation Foundation Models with Reinforcement LearningInternational Conference on Learning Representations (ICLR), 2026
- Joint Optimization for 4D Human-Scene Reconstruction in the WildInternational Conference on Learning Representations (ICLR), 2026
- Learning Sidewalk Autopilot from Multi-Scale Imitation with Corrective Behavior ExpansionInternational Conference on Robotics and Automation (ICRA), 2026
- AURA: Multi-modal Shared Autonomy for Urban NavigationComputer Vision and Pattern Recognition (CVPR), 2026
2025
- Towards Autonomous Micromobility through Scalable Urban SimulationComputer Vision and Pattern Recognition (CVPR), 2025Highlight
- Vid2Sim: Realistic and Interactive Simulation from Video for Urban NavigationComputer Vision and Pattern Recognition (CVPR), 2025
- MEAT: Multiview Diffusion Model for Human Generation on Megapixels with Mesh AttentionComputer Vision and Pattern Recognition (CVPR), 2025
- Learning to Generate Diverse Pedestrian Movements from Web Videos with Noisy LabelsInternational Conference on Learning Representations (ICLR), 2025
- MetaUrban: An Embodied AI Simulation Platform for Urban MicromobilityInternational Conference on Learning Representations (ICLR), 2025Spotlight
2024
- Parameterization-driven Neural Surface Reconstruction for Object-oriented Editing in Neural RenderingEuropean Conference on Computer Vision (ECCV), 2024
- CosmicMan: A Text-to-Image Foundation Model for HumansComputer Vision and Pattern Recognition (CVPR), 2024Highlight
-
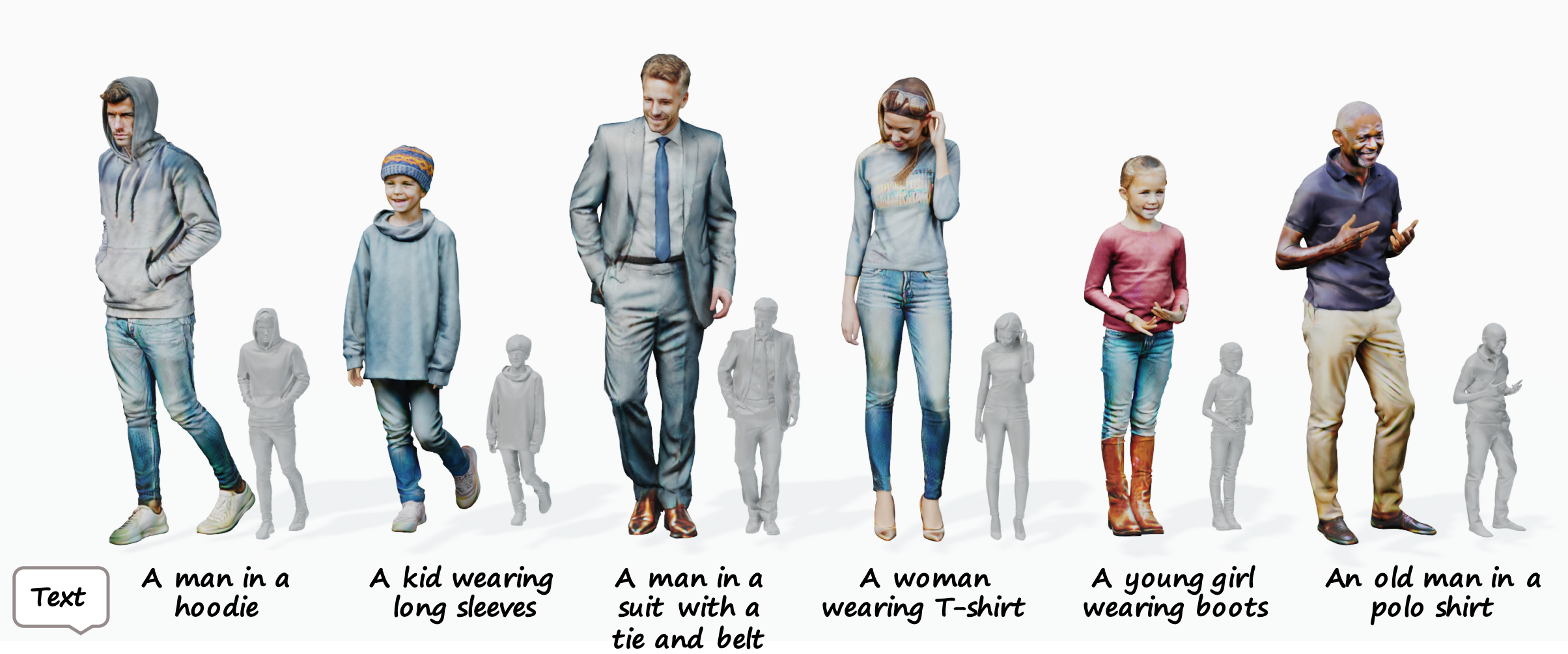 PaintHuman: Towards High-fidelity Text-to-3D Human Texturing via Denoised Score DistillationAssociation for the Advancement of Artificial Intelligence (AAAI), 2024
PaintHuman: Towards High-fidelity Text-to-3D Human Texturing via Denoised Score DistillationAssociation for the Advancement of Artificial Intelligence (AAAI), 2024 -
 ReliTalk: Relightable Talking Portrait Generation from a Single VideoInternational Journal of Computer Vision (IJCV), 2024
ReliTalk: Relightable Talking Portrait Generation from a Single VideoInternational Journal of Computer Vision (IJCV), 2024 -
 VLG: General Video Recognition with Web Textual KnowledgeInternational Journal of Computer Vision (IJCV), 2024
VLG: General Video Recognition with Web Textual KnowledgeInternational Journal of Computer Vision (IJCV), 2024



2023
-
 HyperStyle3D: Text-Guided 3D Portrait Stylization via HypernetworksTechnical report, arXiv:2304.09463, 2023
HyperStyle3D: Text-Guided 3D Portrait Stylization via HypernetworksTechnical report, arXiv:2304.09463, 2023 - RenderMe-360: A Large Digital Asset Library and Benchmarks Towards High-fidelity Head AvatarsNeural Information Processing Systems (NeurIPS), Datasets and Benchmarks, 2023
- DNA-Rendering: A Diverse Neural Actor Repository for High-Fidelity Human-centric RenderingInternational Conference on Computer Vision (ICCV), 2023
- SynBody: Synthetic Dataset with Layered Human Models for 3D Human Perception and ModelingInternational Conference on Computer Vision (ICCV), 2023
- UnitedHuman: Harnessing Multi-Source Data for High-Resolution Human GenerationInternational Conference on Computer Vision (ICCV), 2023
- OrthoPlanes: A Novel Representation for Better 3D-Awareness of GANsInternational Conference on Computer Vision (ICCV), 2023
- 3DHumanGAN: Towards Photo-Realistic 3D-Aware Human Image GenerationInternational Conference on Computer Vision (ICCV), 2023
- MotionBERT: Unified Pretraining for Human Motion AnalysisInternational Conference on Computer Vision (ICCV), 2023
- Text2Performer: Text-Driven Human Video GenerationInternational Conference on Computer Vision (ICCV), 2023
- Learning Unified Decompositional and Compositional NeRF for Editable Novel View SynthesisInternational Conference on Computer Vision (ICCV), 2023
- MonoHuman: Animatable Human Neural Field from Monocular VideoConference on Computer Vision and Pattern Recognition (CVPR), 2023
- CelebV-Text: A Large-Scale Facial Text-Video DatasetConference on Computer Vision and Pattern Recognition (CVPR), 2023
-
 OmniObject3D: Large-Vocabulary 3D Object Dataset for Realistic Perception, Reconstruction and GenerationConference on Computer Vision and Pattern Recognition (CVPR), 2023Best Paper Candidate
OmniObject3D: Large-Vocabulary 3D Object Dataset for Realistic Perception, Reconstruction and GenerationConference on Computer Vision and Pattern Recognition (CVPR), 2023Best Paper Candidate -
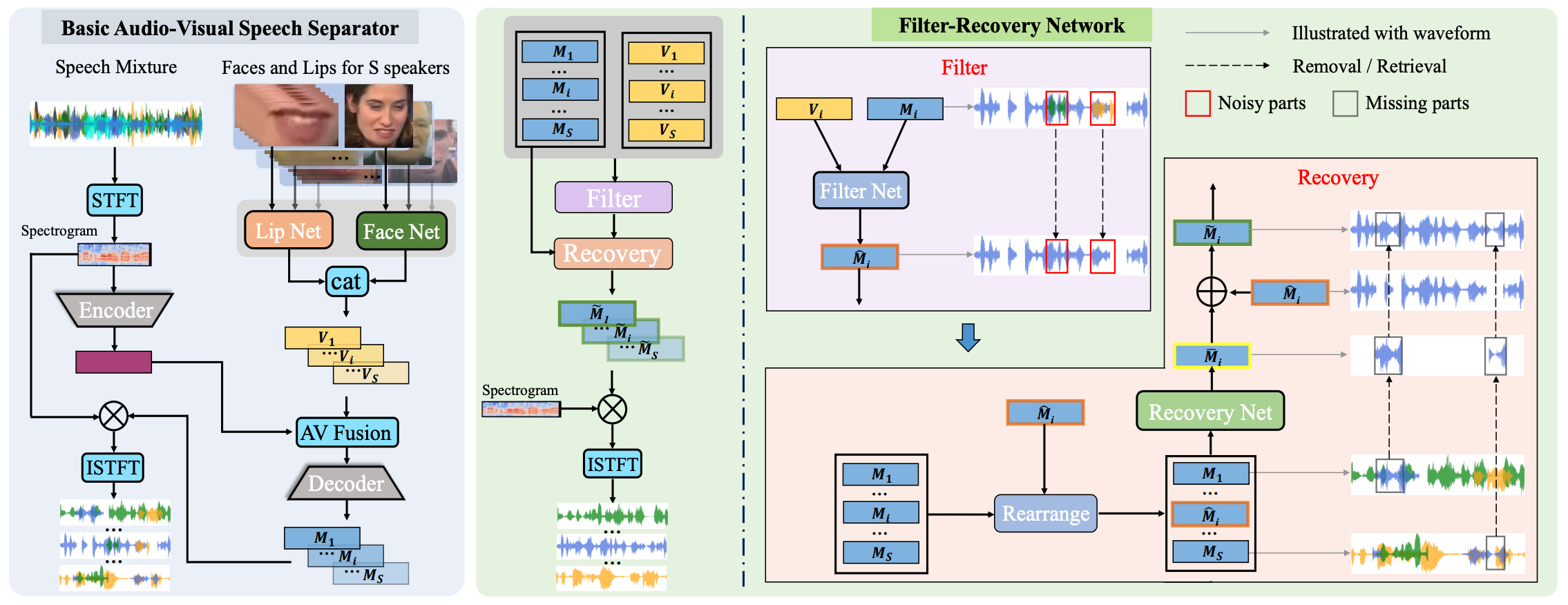 Filter-Recovery Network for Multi-Speaker Audio-Visual Speech SeparationInternational Conference on Learning Representations (ICLR), 2023
Filter-Recovery Network for Multi-Speaker Audio-Visual Speech SeparationInternational Conference on Learning Representations (ICLR), 2023



2022
- Generalizable Neural Performer: Learning Robust Radiance Fields for Human Novel View SynthesisTechnical report, arXiv:2204.11798, 2022
- StyleFaceV: Face Video Generation via Decomposing and Recomposing Pretrained StyleGAN3Technical report, arXiv:2208.07862, 2022
- Audio-Driven Co-Speech Gesture Video GenerationNeural Information Processing Systems (NeurIPS), 2022Spotlight
- Fast-Vid2Vid: Spatial-Temporal Compression for Video-to-Video SynthesisEuropean Conference on Computer Vision (ECCV), 2022
- StyleGAN-Human: A Data-Centric Odyssey of Human GenerationEuropean Conference on Computer Vision (ECCV), 2022
-
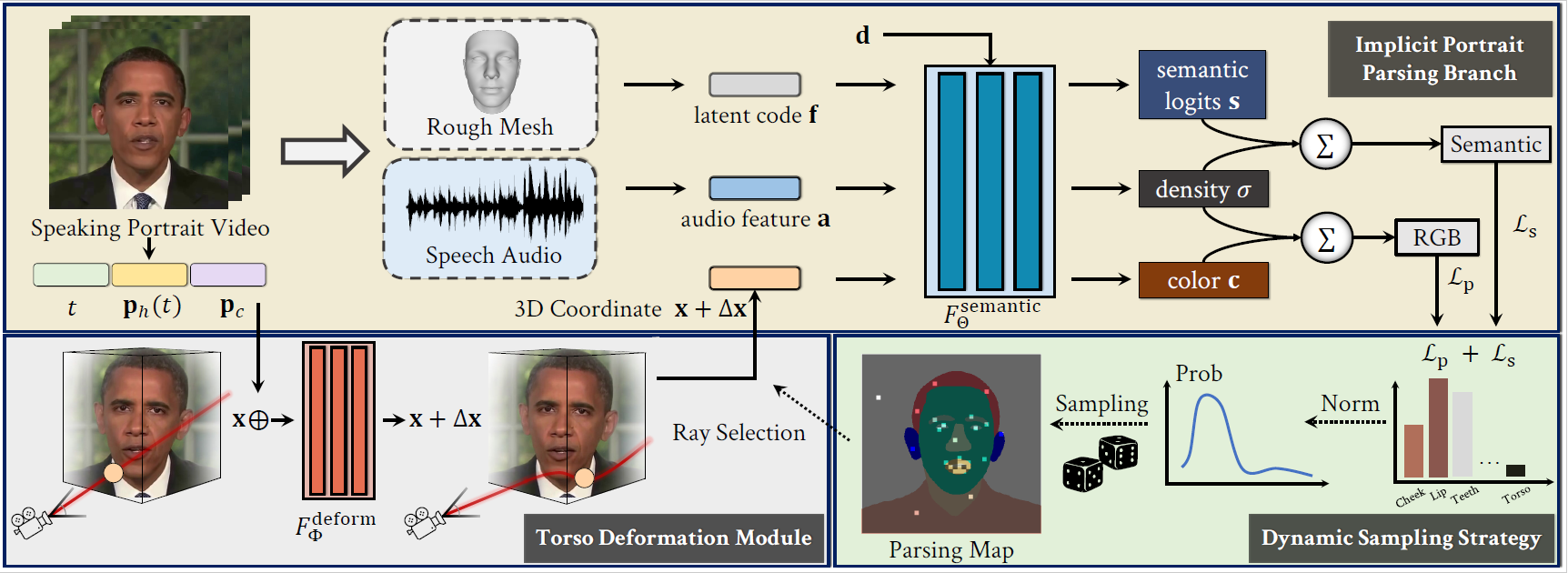 Semantic-Aware Implicit Neural Audio-Driven Video Portrait GenerationEuropean Conference on Computer Vision (ECCV), 2022Oral
Semantic-Aware Implicit Neural Audio-Driven Video Portrait GenerationEuropean Conference on Computer Vision (ECCV), 2022Oral - CelebV-HQ: A Large-Scale Video Facial Attributes DatasetEuropean Conference on Computer Vision (ECCV), 2022
-
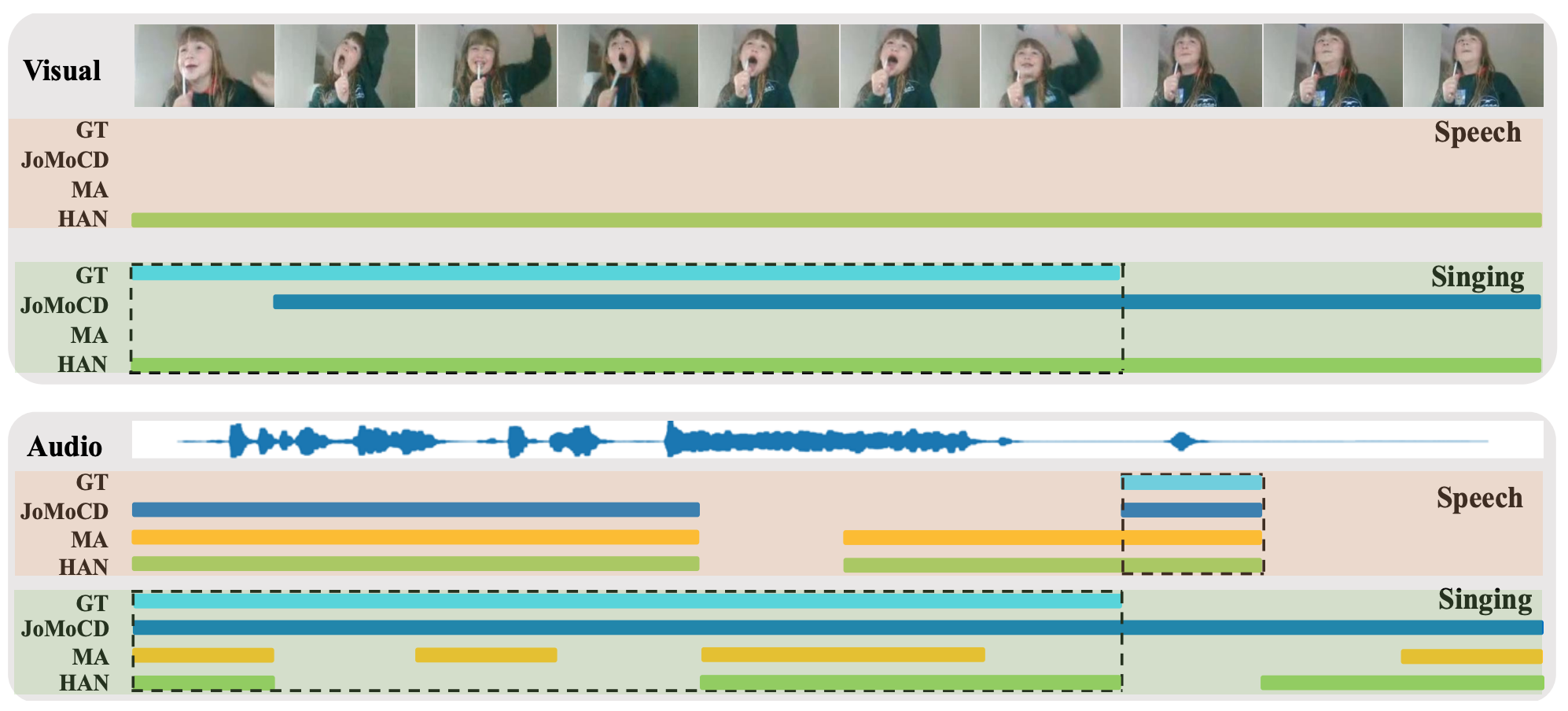 Joint-Modal Label Denoising for Weakly-Supervised Audio-Visual Video ParsingEuropean Conference on Computer Vision (ECCV), 2022
Joint-Modal Label Denoising for Weakly-Supervised Audio-Visual Video ParsingEuropean Conference on Computer Vision (ECCV), 2022 - Text2Human: Text-Driven Controllable Human Image GenerationACM Transaction on Graphics (SIGGRAPH), 2022
-
 TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial EditingConference on Computer Vision and Pattern Recognition (CVPR), 2022
TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial EditingConference on Computer Vision and Pattern Recognition (CVPR), 2022 - Learning Hierarchical Cross-Modal Association for Co-Speech Gesture GenerationConference on Computer Vision and Pattern Recognition (CVPR), 2022
-
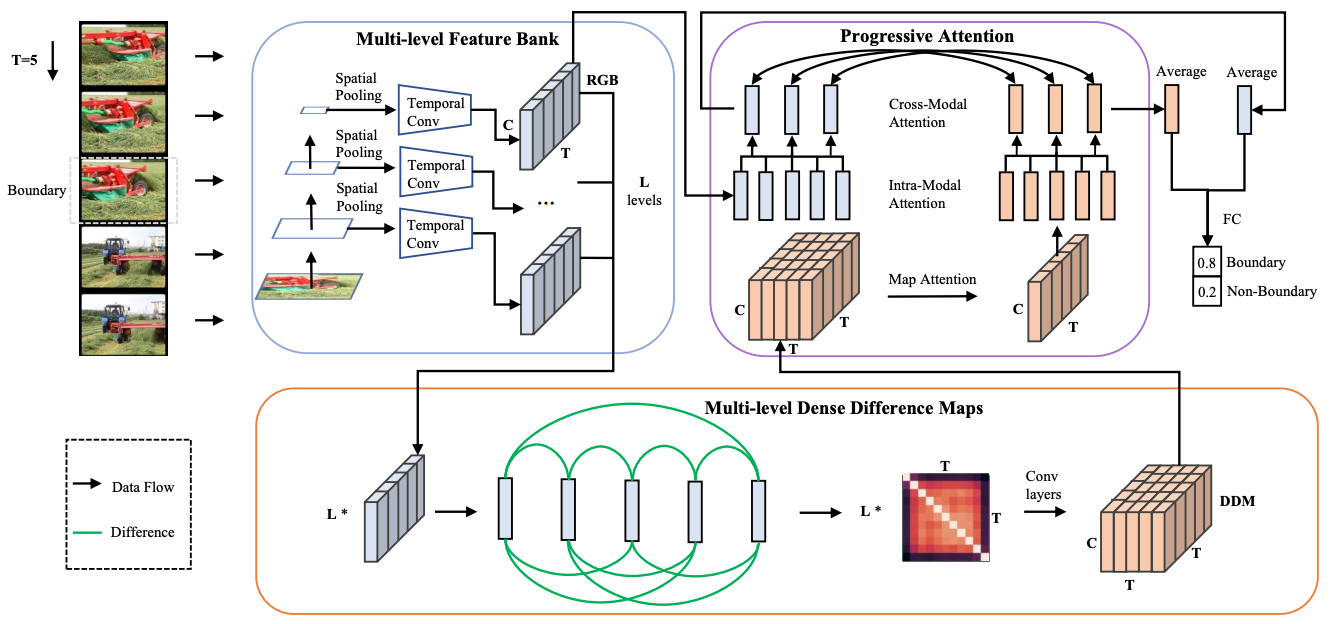 Progressive Attention on Multi-Level Dense Difference Maps for Generic Event Boundary DetectionConference on Computer Vision and Pattern Recognition (CVPR), 2022
Progressive Attention on Multi-Level Dense Difference Maps for Generic Event Boundary DetectionConference on Computer Vision and Pattern Recognition (CVPR), 2022 -
 MoCaNet: Motion Retargeting in-the-wild via Canonicalization NetworksAssociation for the Advancement of Artificial Intelligence (AAAI), 2022
MoCaNet: Motion Retargeting in-the-wild via Canonicalization NetworksAssociation for the Advancement of Artificial Intelligence (AAAI), 2022 - Everybody’s Talkin’: Let Me Talk as You WantTransactions on Information Forensics and Security (TIFS) 2022
-
 DeepFakes Detection: The DeeperForensics Dataset and ChallengeHandbook of Digital Face Manipulation and Detection, Springer, 2022
DeepFakes Detection: The DeeperForensics Dataset and ChallengeHandbook of Digital Face Manipulation and Detection, Springer, 2022 -
 Talking Faces: Audio-to-Video Face GenerationHandbook of Digital Face Manipulation and Detection, Springer, 2022
Talking Faces: Audio-to-Video Face GenerationHandbook of Digital Face Manipulation and Detection, Springer, 2022






2021
-
 Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited DataNeural Information Processing System (NeurIPS), 2021
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited DataNeural Information Processing System (NeurIPS), 2021 -
 Focal Frequency Loss for Image Reconstruction and SynthesisInternational Conference on Computer Vision (ICCV), 2021
Focal Frequency Loss for Image Reconstruction and SynthesisInternational Conference on Computer Vision (ICCV), 2021 -
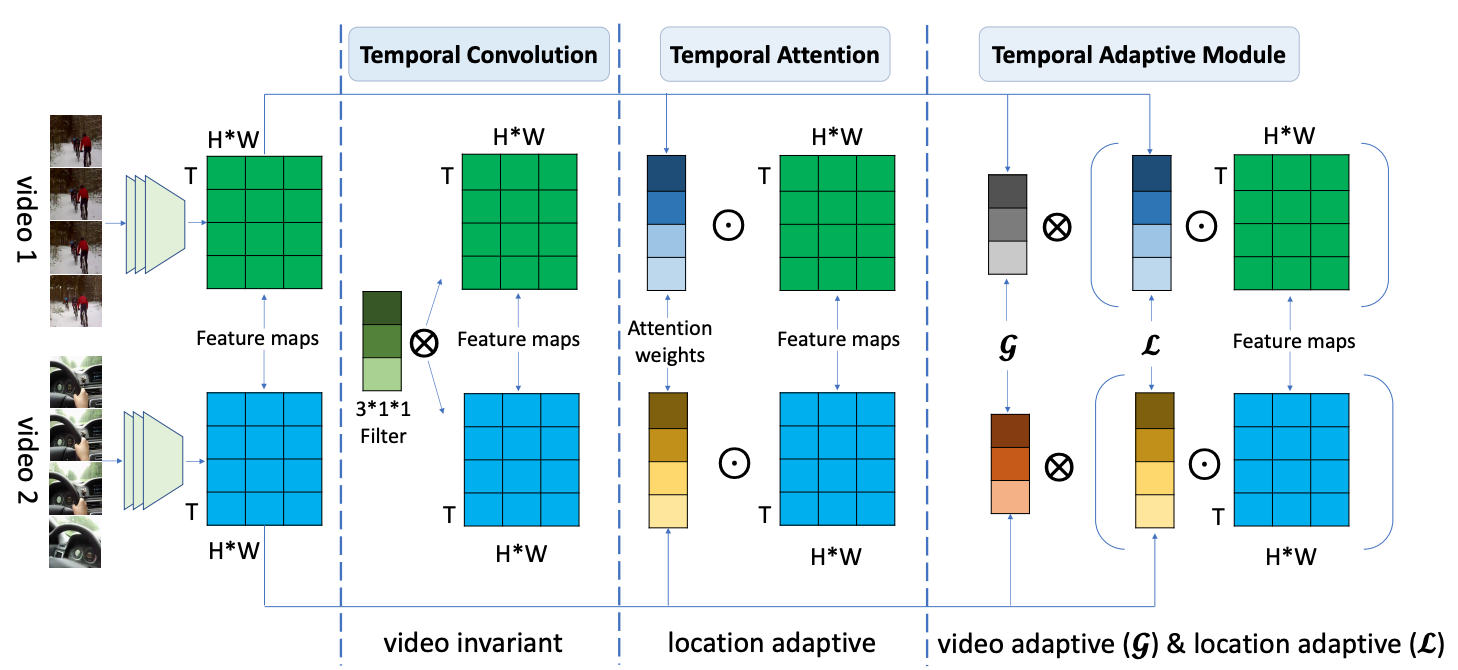 TAM: Temporal Adaptive Module for Video RecognitionInternational Conference on Computer Vision (ICCV), 2021
TAM: Temporal Adaptive Module for Video RecognitionInternational Conference on Computer Vision (ICCV), 2021 - Everything’s Talkin’: Pareidolia Face ReenactmentConference on Computer Vision and Pattern Recognition (CVPR), 2021
- Audio-Driven Emotional Video PortraitsConference on Computer Vision and Pattern Recognition (CVPR), 2021
- Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual RepresentationConference on Computer Vision and Pattern Recognition (CVPR), 2021



2020
-
 AOT: Appearance Optimal Transport Based Identity Swapping for Forgery DetectionNeural Information Processing System (NeurIPS), 2020
AOT: Appearance Optimal Transport Based Identity Swapping for Forgery DetectionNeural Information Processing System (NeurIPS), 2020 -
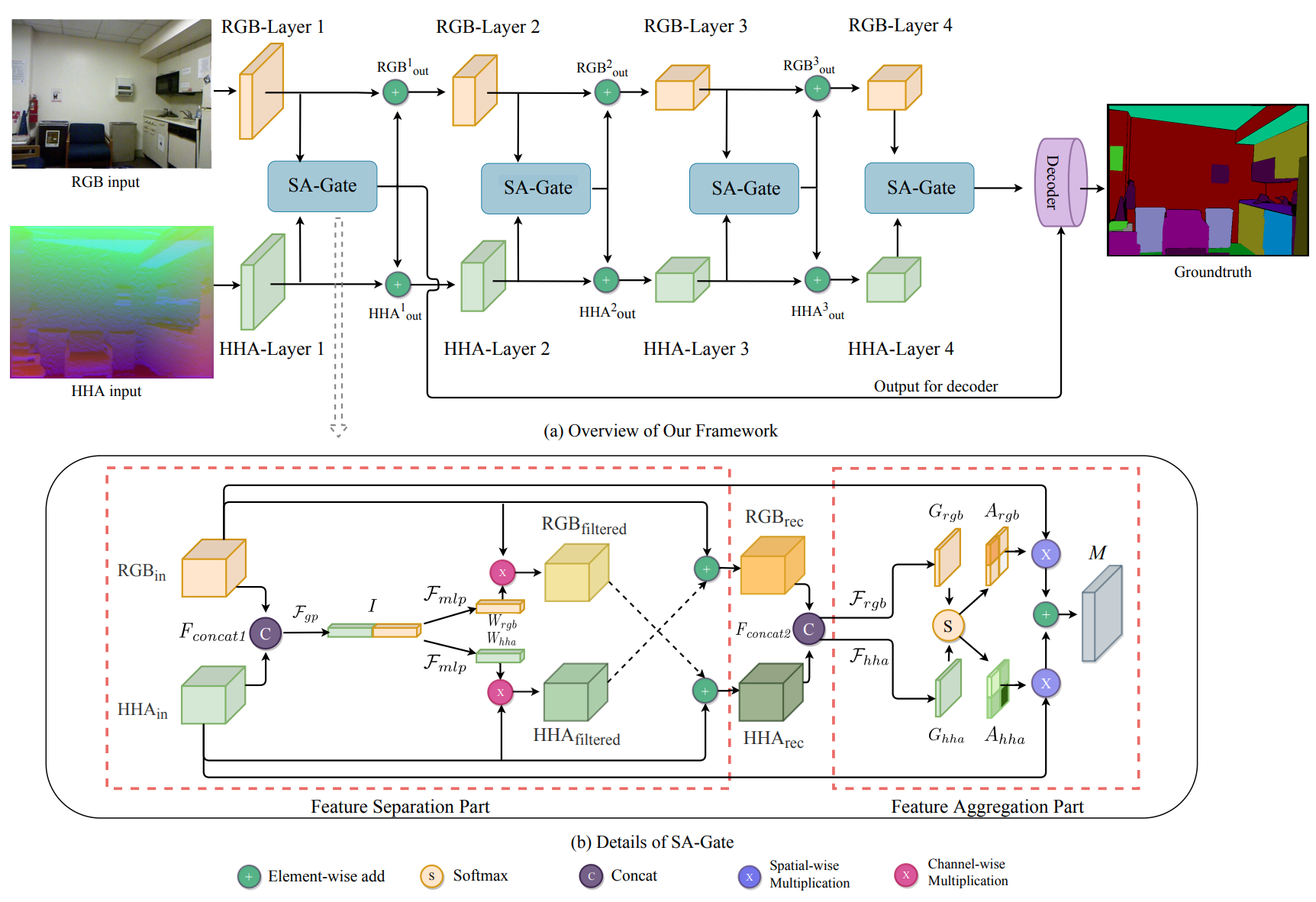 Bi-directional Cross-Modality Feature Propagation with SA Gate for RGB-D Semantic SegmentationEuropean Conference on Computer Vision (ECCV), 2020
Bi-directional Cross-Modality Feature Propagation with SA Gate for RGB-D Semantic SegmentationEuropean Conference on Computer Vision (ECCV), 2020 -
 MEAD: A Large-Scale Audio-Visual Dataset for Emotional Talking-Face GenerationEuropean Conference on Computer Vision (ECCV), 2020
MEAD: A Large-Scale Audio-Visual Dataset for Emotional Talking-Face GenerationEuropean Conference on Computer Vision (ECCV), 2020 -
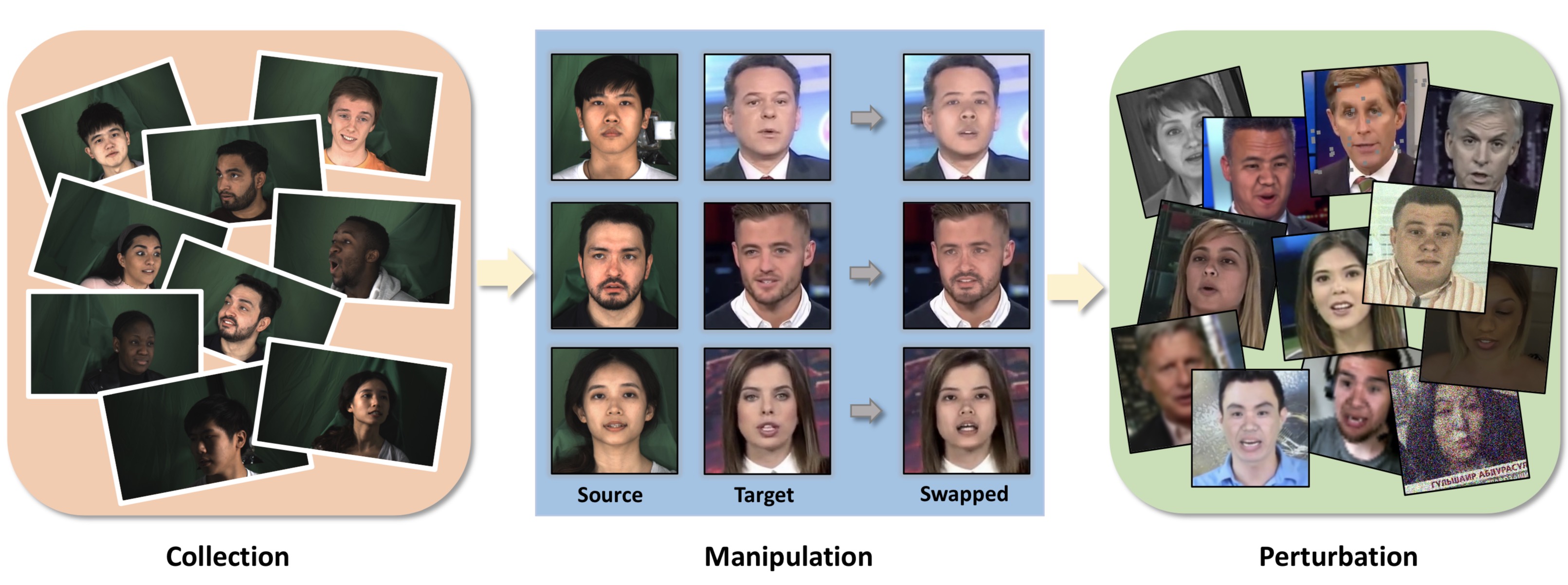 DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery DetectionConference on Computer Vision and Pattern Recognition (CVPR), 2020
DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery DetectionConference on Computer Vision and Pattern Recognition (CVPR), 2020 - TransMoMo: Invariance-Driven Unsupervised Video Motion RetargetingConference on Computer Vision and Pattern Recognition (CVPR), 2020




2019
-
 TransGaGa: Geometry-Aware Unsupervised Image-to-Image TranslationConference on Computer Vision and Pattern Recognition (CVPR), 2019
TransGaGa: Geometry-Aware Unsupervised Image-to-Image TranslationConference on Computer Vision and Pattern Recognition (CVPR), 2019 -
 FAB: A Robust Facial Landmark Detection Framework for Motion-Blurred VideosInternational Conference on Computer Vision (ICCV), 2019
FAB: A Robust Facial Landmark Detection Framework for Motion-Blurred VideosInternational Conference on Computer Vision (ICCV), 2019 -
 Aggregation via Separation: Boosting Facial Landmark Detector with Self-Supervised Style TransitionInternational Conference on Computer Vision (ICCV), 2019
Aggregation via Separation: Boosting Facial Landmark Detector with Self-Supervised Style TransitionInternational Conference on Computer Vision (ICCV), 2019 -
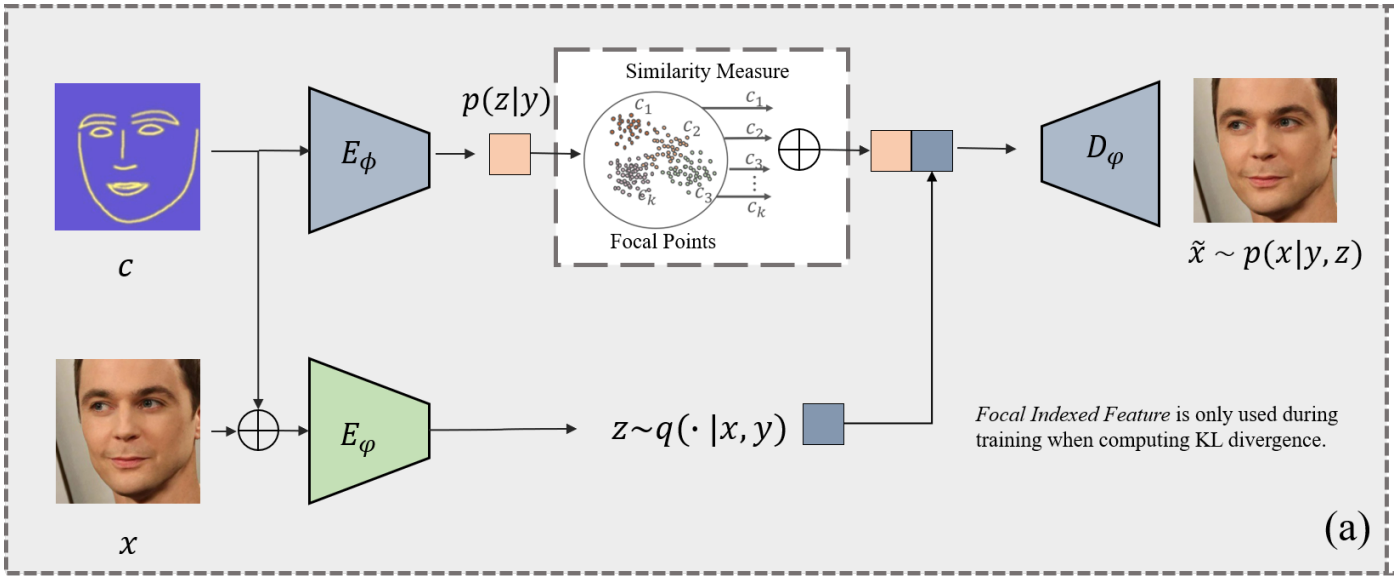 Make a Face: Towards Arbitrary High Fidelity Face ManipulationInternational Conference on Computer Vision (ICCV), 2019
Make a Face: Towards Arbitrary High Fidelity Face ManipulationInternational Conference on Computer Vision (ICCV), 2019



2018
- ReenactGAN: Learning to Reenact Faces via Boundary TransferEuropean Conference on Computer Vision (ECCV), 2018
- Look at Boundary: A Boundary-Aware Face Alignment AlgorithmConference on Computer Vision and Pattern Recognition (CVPR), 2018