One-shot Face Reenactment
Abstract
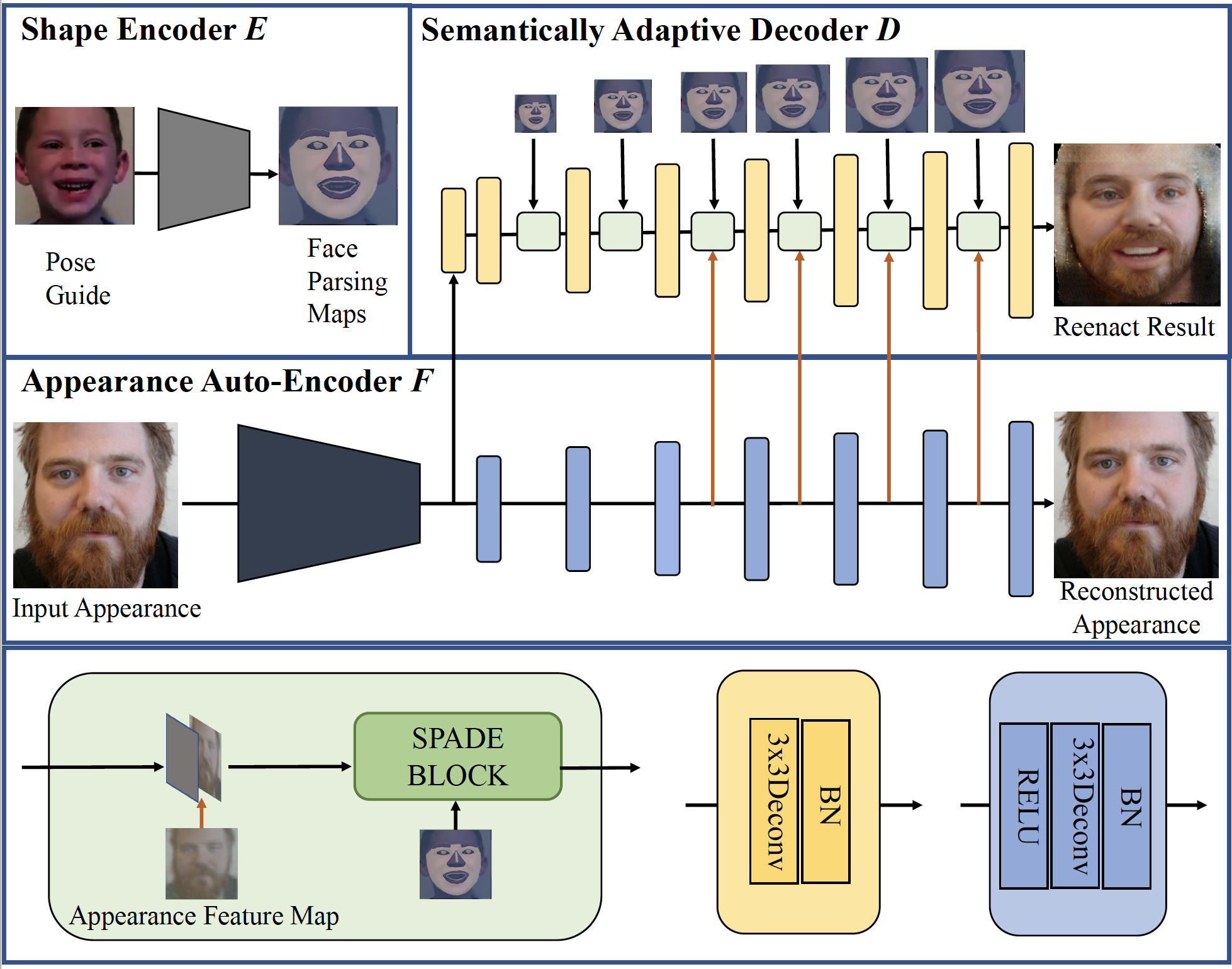
To enable realistic shape (e.g. pose and expression) transfer, existing face reenactment methods rely on a set of target faces for learning subject-specific traits. However, in real-world scenario end users often only have one target face at hand, rendering the existing methods inapplicable. In this work, we bridge this gap by proposing a novel one-shot face reenactment learning system. Our key insight is that the one-shot learner should be able to disentangle and compose appearance and shape information for effective modeling. Specifically, the target face appearance and the source face shape are first projected into latent spaces with their corresponding encoders. Then these two latent spaces are associated by learning a shared decoder which aggregates multi-level features to produce the final reenactment results. To further improve the synthesizing quality on mustache and hair regions, we additionally propose FusionNet which combines the strengths of our learned decoder and the traditional warping method. Extensive experiments show that our one-shot face reenactment system achieves superior transfer fidelity as well as identity preserving than other alternatives. More remarkably, our approach trained with only one target image per subject achieves competitive results to those using a set of target images, which demonstrates the practical merit of this work.
Demo
Downloads



Citation
@inproceedings{zhang2019one,
author = {Zhang, Yunxuan and Zhang, Siwei and He, Yue and Li, Cheng and Loy, Chen Change and Liu, Ziwei},
title = {One-shot Face Reenactment},
booktitle = {BMVC},
month = September,
year = {2019}
}